
Word spotting use a query word image to find any instances of that word among document images. The obtained list of words is ranked according to similarity to the query word. Ideally, any false positives should only occur in the end of that list. However, in reality they often occur higher up, which decreases the so called mean average precision. The idea of Consensus Ranking is to create n new ranked lists by re-scoring using the top n occurrences in the original list, and then fusing the scores. This will often increase the mean average precision.
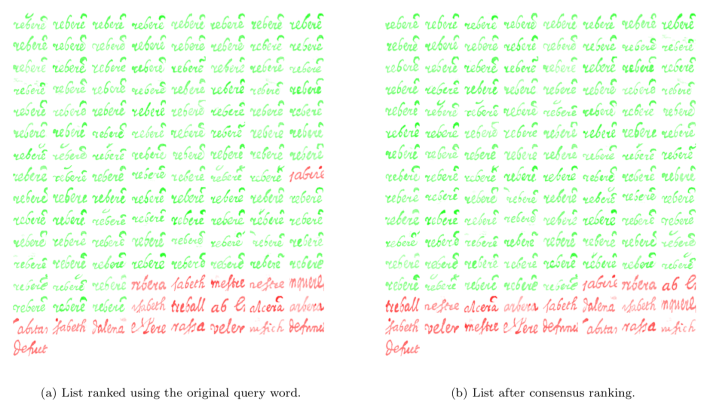
The figure above shows the difference between the original list (a) and the list ranked using consensus ranking (b). Generally a better ranking is created when the top n words are true positives, but it can also handle quite well cases when there happen to be a few a false positives among them.
Another advantage with this approach is that the confidence value is recomputed in the fusion process. This means that some words will have a lower score than the one computed in the original search (the paper also discuss how to use it with Query Expansion). The advantage with the fused score is that it is possible to purge the list by removing those words that fall under a certain threshold.
- Consensus Ranking for Increasing Mean Average Precision in Keyword Spotting.
A. Hast.
VIPERC 2020, Proceedings of 2nd International Workshop on Visual Pattern Extraction and Recognition for Cultural Heritage Understanding. co-located with 16th Italian Research Conference on Digital Libraries (IRCDL 2020) Bari, Italy, January 29, 2020.
pp. 46-57, 2020. pdf
